SeleniumIDEを使ってページングしている.aspxサイトの情報をなるべくノンプラグラミングで取得してみた
Contents
通常のサイトだとhtmlパラメータを使って情報を取得できるところが多いので、Firefixの拡張機能であるSeleniumIDEを使うだけで簡単に情報を取得してくることができます。 しかし、aspx系のサイトだとソース内部で情報を持っており、htmlのパラメータだけでは情報取得することが出来ません。 そこで、若干ソースをいじることで(!)aspx系のサイトもノンプラミングでやろうと思いました。
実行環境
実行環境としては、Mac OS Seriaを想定します。
下準備
下記コマンドをターミナルから実行してください。
pip install selenium bs4brew install geckodriver
基礎となるソースの生成
ここでSeleniumIDEを使います。
取得したいサイトで想定される繰り返し動作をSeleniumIDEでレコーディングします。
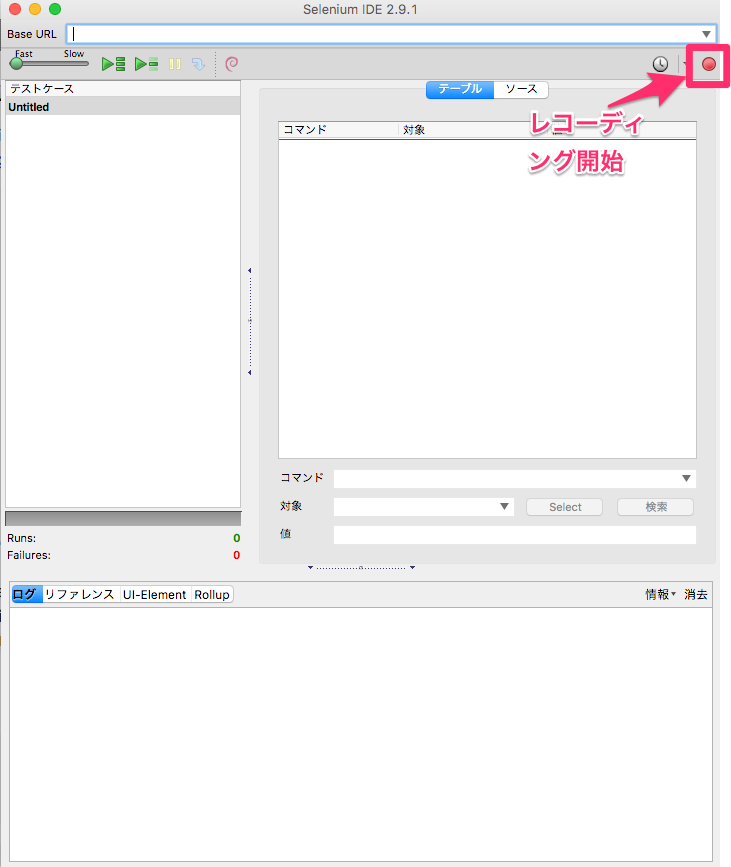 そうするとテーブルのところにコマンドが表示されてきます。
そうするとテーブルのところにコマンドが表示されてきます。
コマンドが確認出来たら
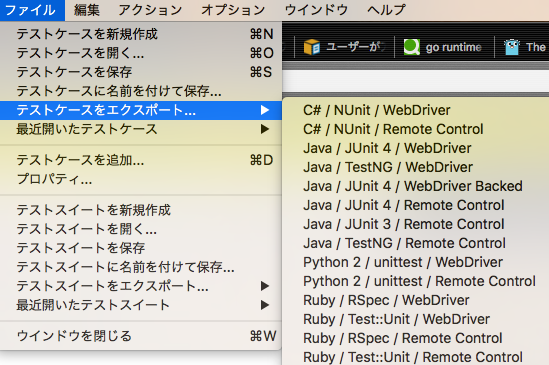 ここからエクスポートしたい言語を選びエクスポートすると、その時点でのソースが表示されます。
python2/unittest/webdriver で保存後、ソースを開くと、
ここからエクスポートしたい言語を選びエクスポートすると、その時点でのソースが表示されます。
python2/unittest/webdriver で保存後、ソースを開くと、
| |
という箇所があると思いますが、そこが実際に処理を行うところとなります。
繰り返し処理の作成
繰り返し処理はpythonの場合いくつかありますが、基本的に1-30ページを繰り返したいとかだと思うので、rangeを使います。繰り返したい箇所が下記のようなところであれば
| |
という形で繰り返し文を繰り返したい場所の前でfor i range(1, 30):をいれ、繰り返したいところだけインデントをします。
その後、page 1などのページ数に値する数字のところをみつけ、そこをpage" + str(i) + "に変更します。
ページの情報を取得
ページの情報を取得する場合はhtml整形ツールを使うのですが、今回はBeautifulSoup4を使います。
ソースの上の方に
| |
と追加し、ソースを出したいタイミングのところで
| |
をペーストしてください。
<セレクタ>のところはブラウザで右クリックすると出てくる”要素の検証”で出てくるウィンドウで対象のhtmlタグで右クリックし

このCSSパスを選び、それを<セレクタ>と置き換えて下さい。
実行
これで実行できる状態になりました。 ターミナルを開き、
| |
を実行し、test.htmlが作成されれば成功です。
まとめ
全然ノンプラグラミングではなかったので、もっとノンプラグラミングな方法を知っている方教えていただけるとうれしいですw
Author kotamat
LastMod 2017-05-04